Kubernetes operators became quickly popular. Allowing to automate pretty much any task makes a good promise to end users. More and more of them are popping up and they do simplify way of working with various products, projects and components.
Operators are usually bound to custom resources (a kubernetes extension to core objects such as pods, services etc). Custom resource allows us to build a first class citizen objects in kubernetes that represents exactly what we need.
In most of the cases operators are built with Go language. There is SDK to help you out in the process of building your own operator but it does require a decent knowledge about both kubernetes, custom resources and Go as programming language. Sometimes this can be a bit of a show stopper especially if Go is not your primary programming language.
Don’t worry though, there are other options that will help you to take a ride with operators.
So in general an operator’s responsibility is to remove or at least minimise the need for manual work around the provisioning and managing of your custom resources. This can be almost anything from creating config maps or secrets for a given set of items, provisioning data base schema, deploying custom containers or enhancing already deployed. It will depend on your actual needs but what it all has in common is that it usually end up to be some sort of sequence of steps or even a state machine. So the more you look into it the more it looks like a workflow or a process.
So with that ... why not make use of workflow engines to build operators?
You might ask what’s the benefits to use workflows instead of relying solely on operator’s SDK.... let’s have a quick look at them directly
- workflows give direct visibility to the work operator will do, this applies to both development time and runtime - picture is worth 1000 words - or to rephrase it a bit - picture is worth 1000 lines of code
- workflows allow you to take advantage of the built in capability - isolation - as each workflow instance is completely isolated from each other and manages its data independently
- workflows come with many useful features such as error handling, retry, notifications that can involve human actors in specific situations
- workflows are equipped with compensation capabilities to ensure that the work operator does, always stays in consistent state - in case there are failures within then “happy path”, already performed steps can be compensated and thus leave the state of the cluster consistent
Automatiko is a java based project so the approach discussed here will be a java focused but there are also other alternatives that might be worth to explore.
So java and kubernetes operators... what’s available for java developers?
First and foremost is the fabric8 kubernetes client library that allows simple yet very powerful interaction with kubernetes cluster api. To make it even more approachable there is a java operator SDK that is built on top of fabric8 kubernetes client. In addition to that, it also provides Quarkus extension and with that you can build the operator as native image that makes it very efficient in resource utilization and extremely fast to start that is comparable with Go based operators.
Automatiko builds on these two (fabric8 kubernetes client and java operator SDK) and delivers workflow based approach to building operator logic. It is implemented similar to how Automatiko provides support for event streams (IoT, Apache Kafka) via so called message events. Message events is the entry point to the workflow logic. It will receive all events from kubernetes api when custom resource was:
- created
- updated
- deleted
There are two main ways of implementing workflows for operators
- statefull
- stateless
Statefull
Stateful means that workflow instance will be bound to the life time of a custom resource. That means it is created when custom resource is created in the cluster/namespace. That instance stay active as long as custom resource is "alive". It will receive all updates made to the custom resource. Eventually, the same workflow instance will be notified when the custom resource was deleted. Each of these events will trigger logic in the workflow instance that will perform set of steps. The statefull approach mirrors to some extent the custom resource - giving complete view of the custom resource via the workflow instance.
Stateless
Stateless on the other hand does not mirror the custom resource but simply executes the logic of the workflow and ends it. In most of the cases this could lead to having different workflow definitions per type of event - create, update and delete of custom resource.
What's more that workflow can bring?
Another important aspect that workflow enable by default is the ability to interact with human actors. Even though operators are meant to automate things there are always exceptional situations that would require human intervention. Notifications and human assigned tasks can also be useful when there will be a need for extra information during the operator work.
Last but not least worth mentioning feature of workflows that can become handy for operator implementations are time based actions - timers. Timers can be put into your workflow definition to pause further execution until given time elapsed or certain date/time was reached. It could serve as a base for instance for time based auto scaling - bring up more pods of a custom resource for office hours and scale down to only one instance during off work hours.
These are just few arguments that can broaden the view while starting to work with operators. But let’s have a look at something more concrete- so let’s have a look at operator built with workflow.
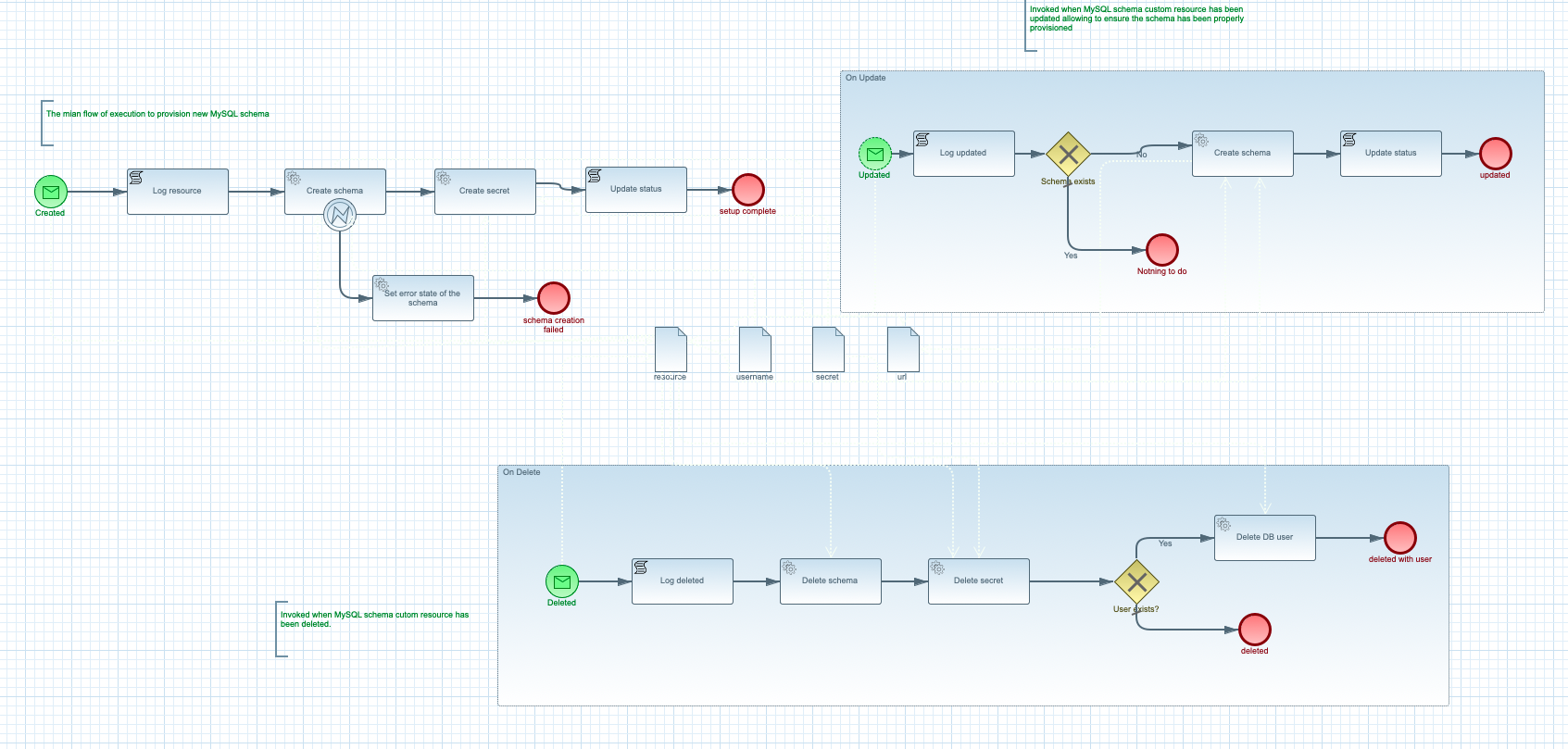 Workflow model of Kubernetes operator that allows MySQL schema provisioning with secrets creation.
Workflow model of Kubernetes operator that allows MySQL schema provisioning with secrets creation.
The above operator follows the statefull approach and models a simple MySQL schema provisioning example.
So there are three distinct entry points that are invoked automatically based on incoming events from kubernetes api
- when new custom resource is created it triggers Created message start event which will then create schema, create secret with password to the schema and update the status. In case there are errors during schema creation, automatic retries will be peformed and in case all retries attempts are taken the custom resource status will be updated with an error.
- when custom resource was updated the Updated message start event is invoked. It will verify the schema exists and if so end or crate it. Note that this is correlated based on custom resource name
- when custom resource is deleted it will invoke Deleted message event that will trigger "clean up" logic
You can see this concept in action in the below video
Conclusion
The idea behind operators is very powerful and it can make life of operation team way easier. In addition to that operators start to gain traction as well for application needs which are less infrastructure focused. Having possibility to build operator logic in the programming language of your application will certainly help to get up to speed rapidly. Regardless of the programming language being used there might be a potential problem with visibility of the operator work. Here workflows come handy and bring set of features to make the operator being more consumable for both development and operation team members.
Photographs by Unsplash.