Apache Kafka event streams consumed by workflows
An inspiration for this blog post is another blog post by Piotr Minkowski that perfectly introduced Kafka Streams with Quarkus. This triggered a thought - can workflows be used as an alternative to Kafka Streams to process multiple event streams (merge them and process various events streams with some correlation logic)?
As a desclaimer - this blog post is to not put workflows as replacement of Kafka Streams but to showcase capabilities that workflows have in terms of event streams.
First of all, please have a read of Piotr's blog post first to understand the use case as this article heavily relies on that understanding. But to set the stage quickly let me quote Piotr's first paragraph of architecture:
"In our case, there are two incoming streams of events. Both of them represent incoming orders. These orders are generated by the order-service application. It sends buy orders to the orders.buy topic and sell orders to the orders.sell topic. Then, the stock-service application receives and handles incoming events. In the first step, it needs to change the key of each message from the orderId to the productId. That’s because it has to join orders from different topics related to the same product in order to execute transactions. Finally, the transaction price is an average of sale and buy prices."
Source code
Source code of the services described in this article can be found
Let's put workflow instead of Kafka Streams as StockService
In the original example stock service was built around Kafka Streams, this article introduces workflow to take that part.
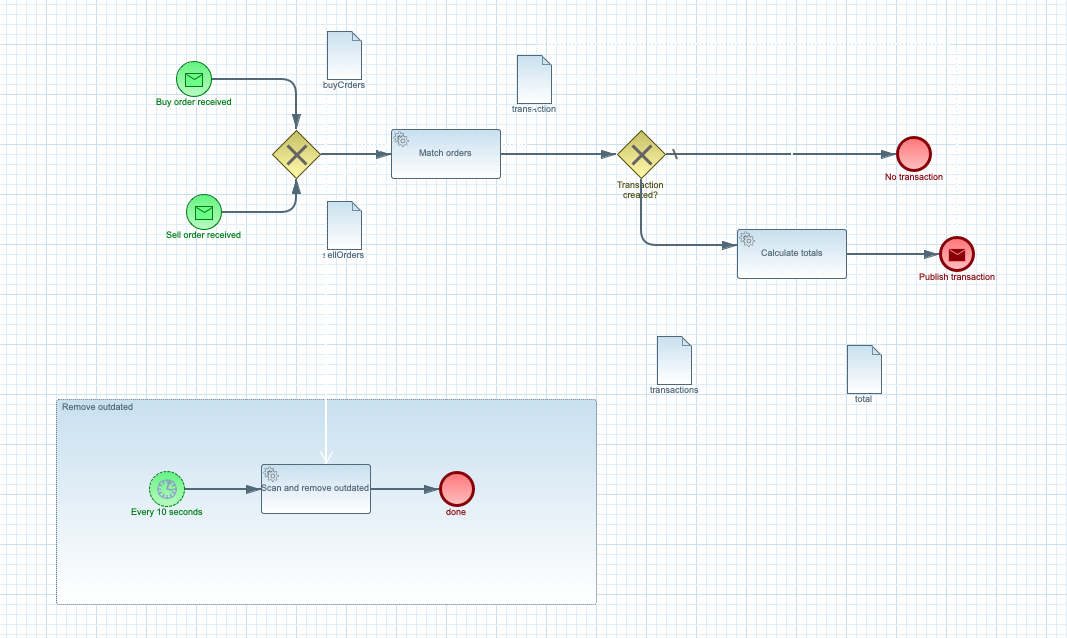 Workflow definition of stock service.
Workflow definition of stock service.
Important aspect to understand is how workflows can merge incoming events from two streams
- orders.buy
- orders.sell
productId. Product id will guide
the business logic to match sell orders with buy orders to generate transaction. This is what Kafka Streams was used for
in the original example.
And that is what workflows can be used for. To receive events from different streams, directly correlate them based on
productId and process to generate transactions. The important part here is that there will be single workflow instance that will process all orders
(both buy and sell) for the same product id. This allows us to handle the use case for analitics around the transactions.
How things are correlated (merge sell and buy orders)?
As can be seen on the workflow diagram, it has two entry points (so called message start events). These two are configured with the
event streams - orders.buy and orders.sell. Each of these message start events uses
correlationExpression to find out what workflow instance should handle given event.
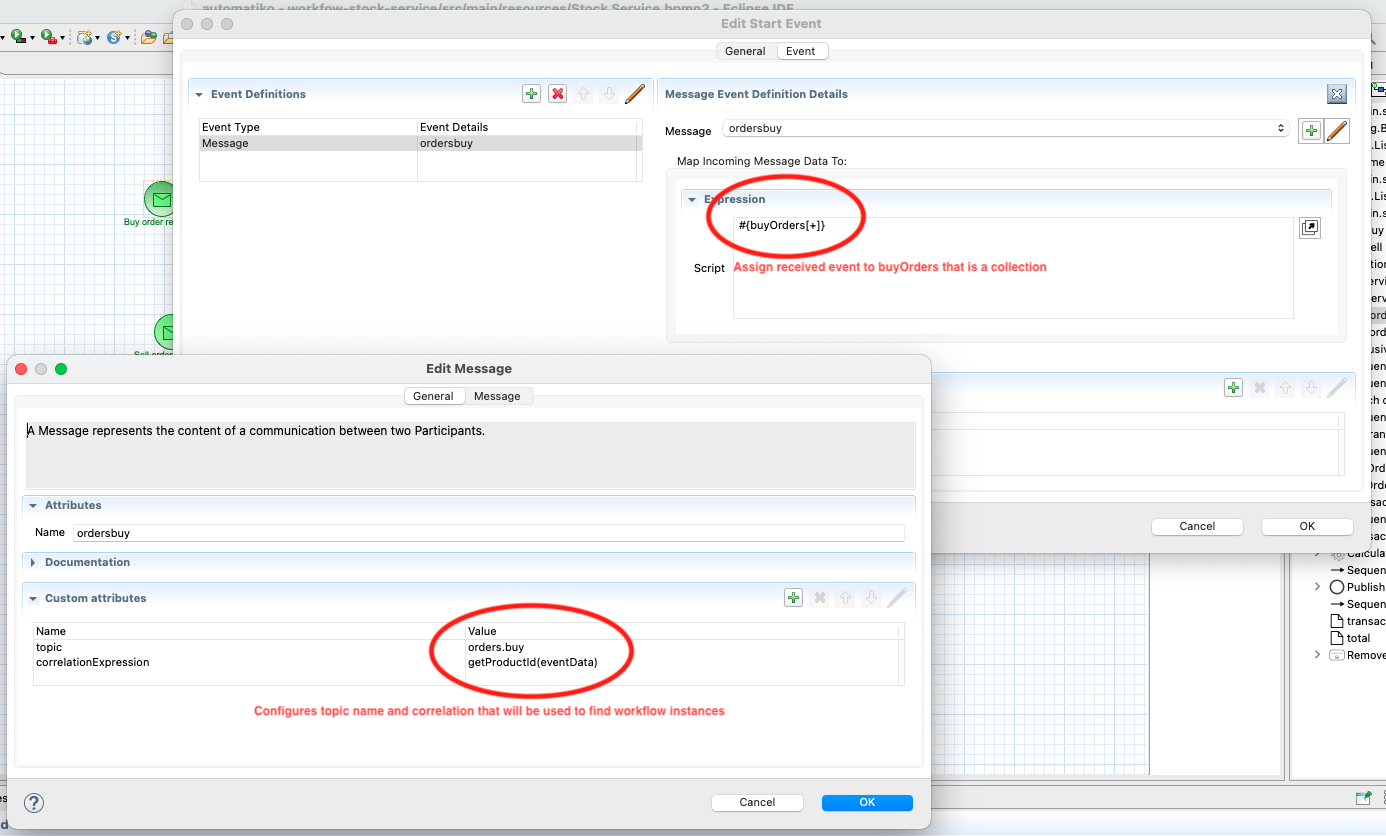 Message correlation expression and topic name.
Message correlation expression and topic name.
In this case correlationExpression is set to getProductId(eventData). This will be evaluated everytime new event is
received, eventData corresponds to variable that will hold the event payload and by that will give access to product id. In this case
getProductId method is a reference to a function that is defined like below.
public class StockFunctions implements Functions {
public static String getProductId(Order eventData) {
return String.valueOf(eventData.getProductId());
}
}
Functions in automatiko are just public static methods on a class that implements io.automatiko.engine.api.Functions. All these methods are then
available for correlation expressions, tags, data mappings, script tasks etc.
In addition, to make this work as expected - that is to process events to either start new instance or call existing instance based on incoming events another setting is required on these start events.
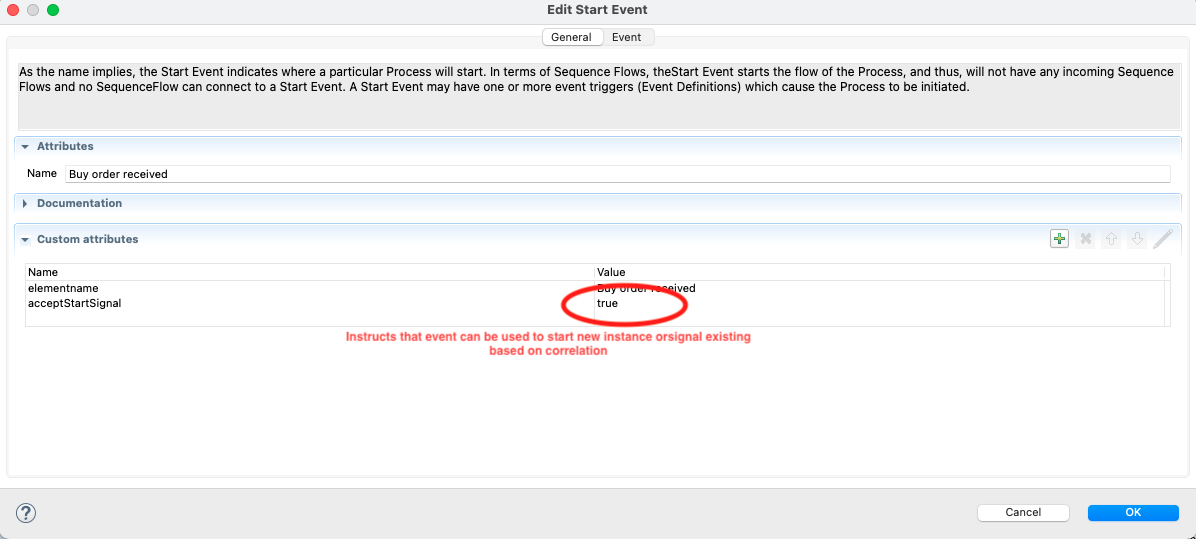 Start event to allow signal via start events.
Start event to allow signal via start events.
Those that know BPMN execution semantics can directly point out that start events will always trigger new instance and thus makes it
impossible to correlate to cover this use case. This is exactly why Automatiko has this extra setting (acceptStartSignal) on the start event that
instructs the execution that start event can be used as both trigger of new instance (if none exists) or signal exising.
Publishing transactions
Upon successful match operation a new transaction is created. That transaction is used to calculate totals (described in next section) and finally published totransactions topic in Apache Kafka. This is done by using message end event that acts in similar way as start event but
produces events instead of consuming them.
Analitics
There is additional part of this example that is responsible for analitics - calculate transaction statistics
- total count of transactions
- total amount of transactions
- total product count of transactions
Analitics can be easily accessed via dedicated endpoints that workflows comes with. Workflow definition is named
stocks and by that this becomes part of the resource endpoint so it can be easily accessed over HTTP
http://localhost:8080/stocks
[
{
"id": "1",
"metadata": null,
"total": {
"amount": 1100,
"count": 6,
"productCount": 1240800
}
},
{
"id": "4",
"metadata": null,
"total": {
"amount": 3300,
"count": 12,
"productCount": 5245200
}
},
...
{
"id": "7",
"metadata": null,
"total": {
"amount": 3200,
"count": 11,
"productCount": 4188700
}
}
]
You can also target single product related information by http://localhost:8080/stocks/1.
On top of that, Automatiko comes with built-in simple management interface that can be used to look at the running instances. To
access this interface go to http://localhost:8080/management/processes/ui
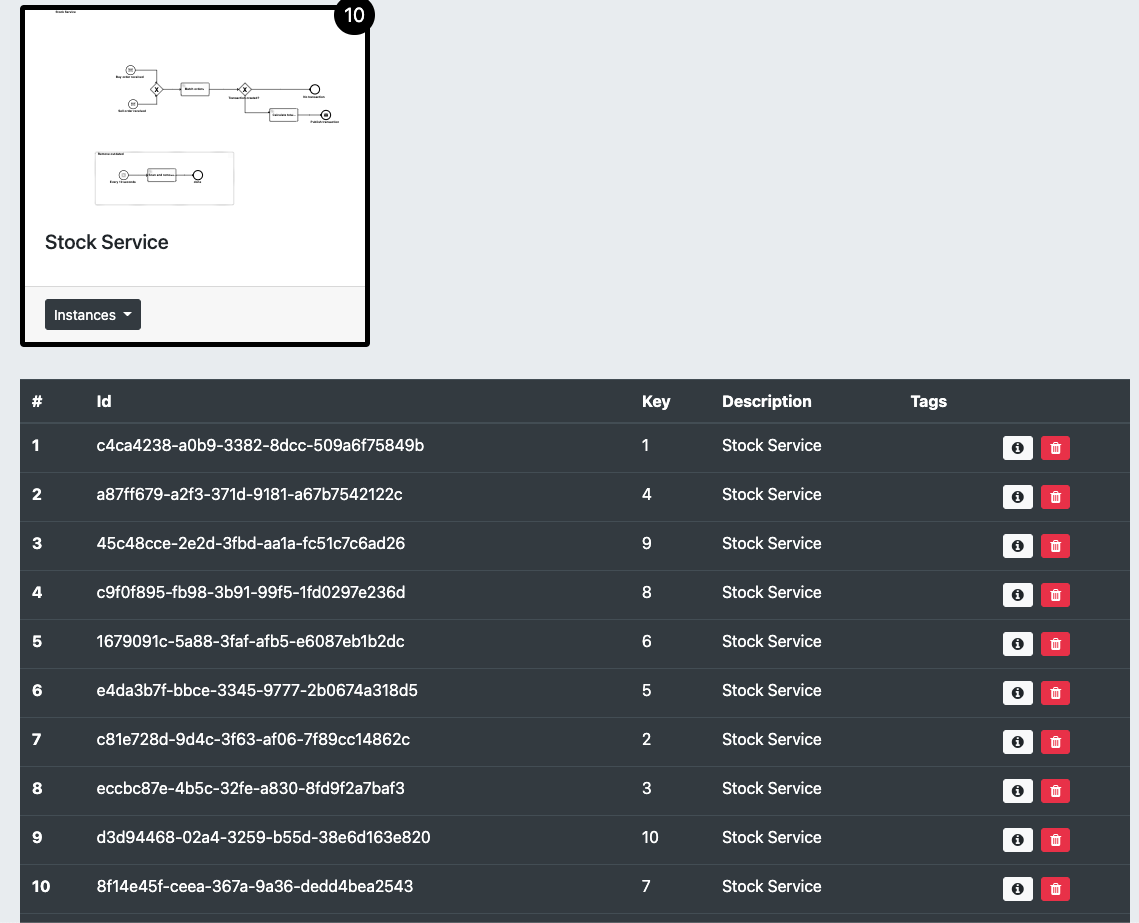 Process management UI.
Process management UI.
Individual instance can be easily viewed by opening details for given row.
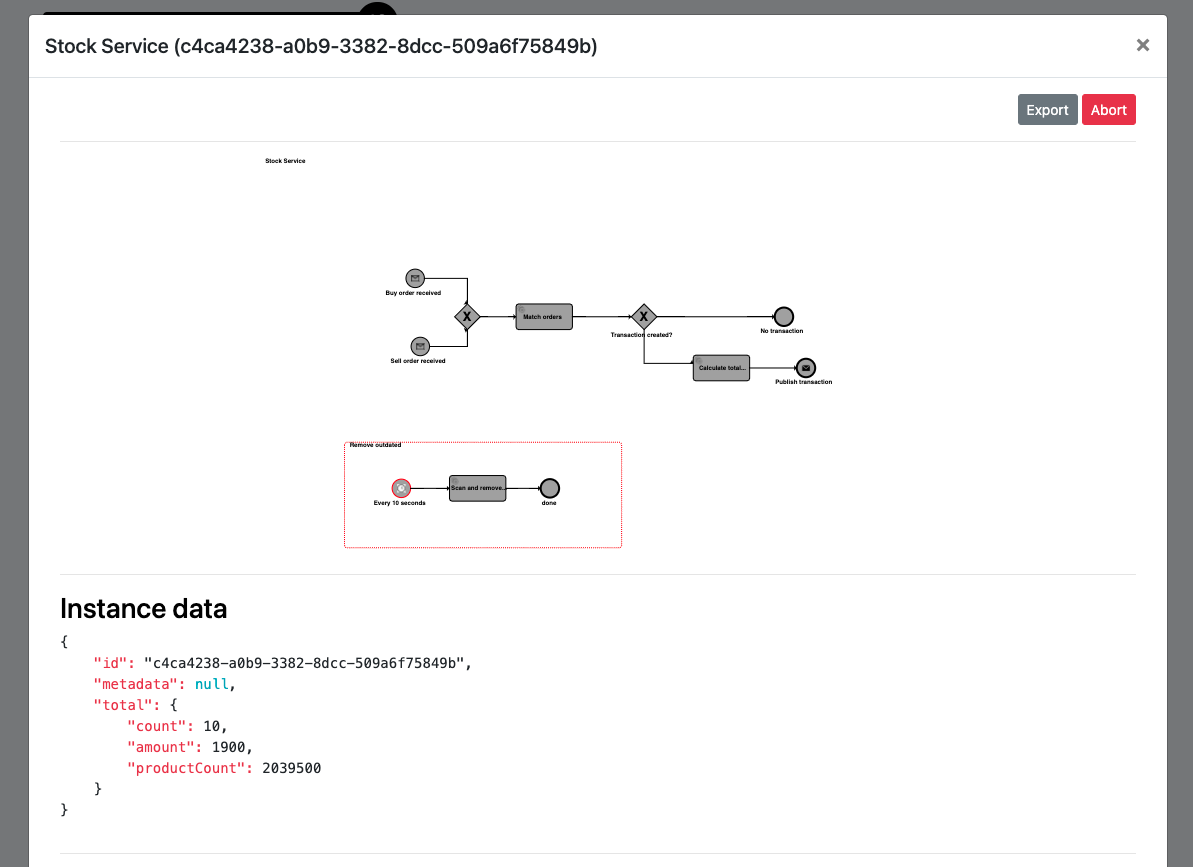 Process management UI - instance details.
Process management UI - instance details.
Remove outdated orders
Last feature of this example service it to remove outdated orders. As mentioned in the original blog post, orders can be processed only when they are not older than 10 seconds. For this exact purpose is the extra workflow fragment (called event subprocess) that will fire off every 10 seconds and do the automatic clean up.
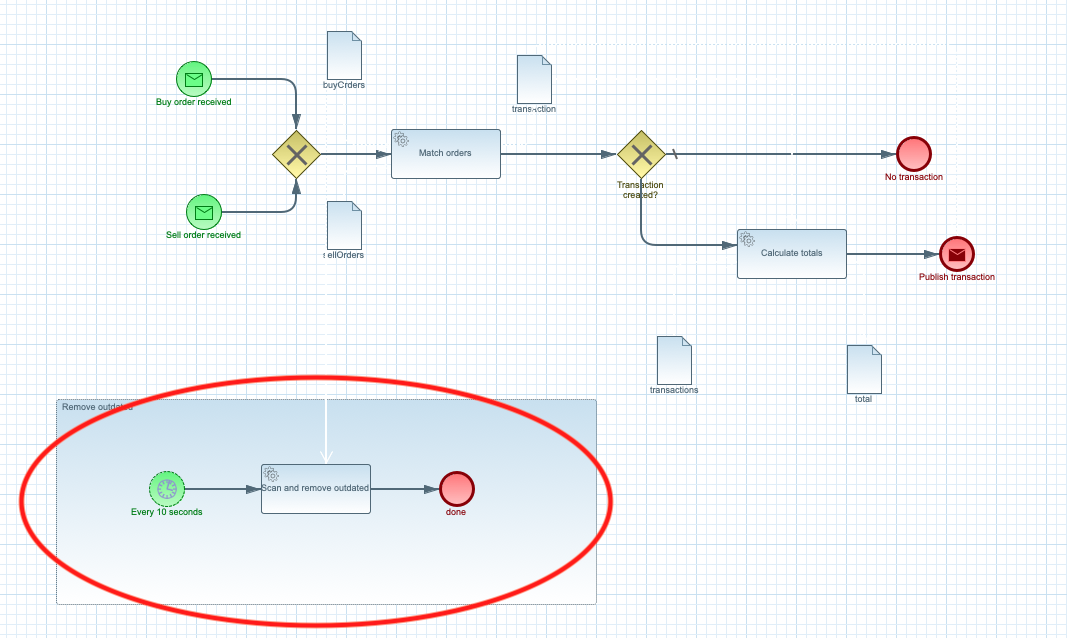 Remove outdated orders on interval.
Remove outdated orders on interval.
Data classification
One thing that people might wonder about is how is it possible that there are several data objects defined in the workflow
buyOrderssellOrderstransactiontransactionstotal
total is visible in the service interface as described and shown in the Analitics section.
The answer to this is - use of data object tags. Tags allow to classify data as
- input
- output
- internal
- transient
- and more...
total is visible as this is the only
one that is marked as output with tag.
Let's see it in action
At the end, have a look at a short screencast showing this example in action.
Thanks for reading and make sure to drop us feedback or ask questions about this article.
Photographs by Unsplash.